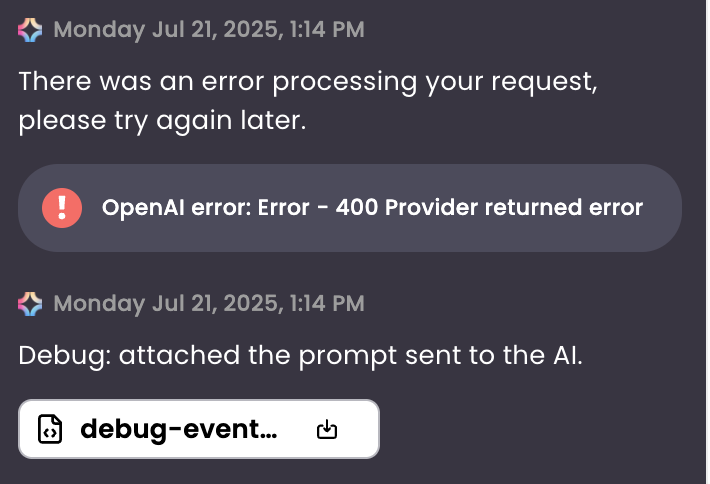
Vibe coding is a rapidly growing field that relies on LLMs’ ability to predict sequences of tokens—in this case, code elements—that achieve a particular intent. This process is probabilistic, which means running the same prompt three times can produce three different outputs, and some of those outputs may include errors that keep the generated code from running. After code is generated, the Boxel system performs simple checks to fix import issues and basic structure automatically. Still, those corrections may not be enough, so another round with the LLM may be required.
The Boxel environment includes a Fix with AI button that sends the error message with one click, giving the LLM a chance to identify the errors and suggest patches. Depending on the error’s nature, one or two passes may be needed. Sometimes you have to locate which template is failing—if the AI generated multiple files in one vibe‑coding pass, click each file and preview its formats; some errors don’t appear until a specific format runs the first time. Use the file tree and Inspector to navigate the cards and fields, find any error messages, and run Fix with AI again to resolve them.
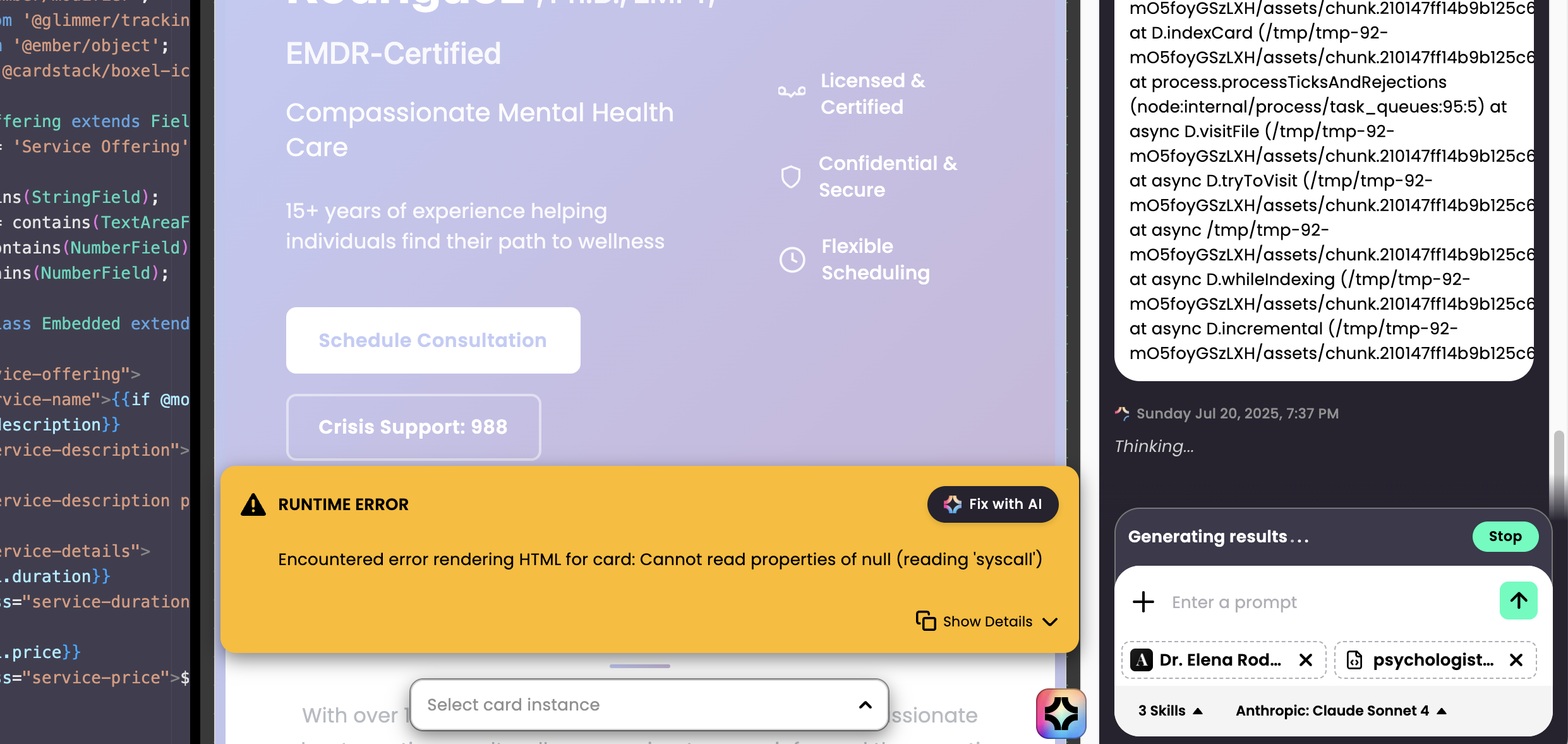
Certain issues can’t be fixed this way and require deeper analysis of code dependencies with a “thinking” model that reasons about root causes. We recommend the Gemini 2.5 Pro model for such debugging. Switch to it with the LLM switcher, copy and paste the error message, and add any relevant GTS or JSON files to give that model full context. A thinking model prints a lot of non‑code text to outline possible errors—these “thinking tokens” provide hints that help create a precise fix. If problems persist, use an outpainting technique (borrowed from image generation): delete the problematic template in the code editor, then ask the LLM to regenerate the fitted template, giving probability another chance to work.
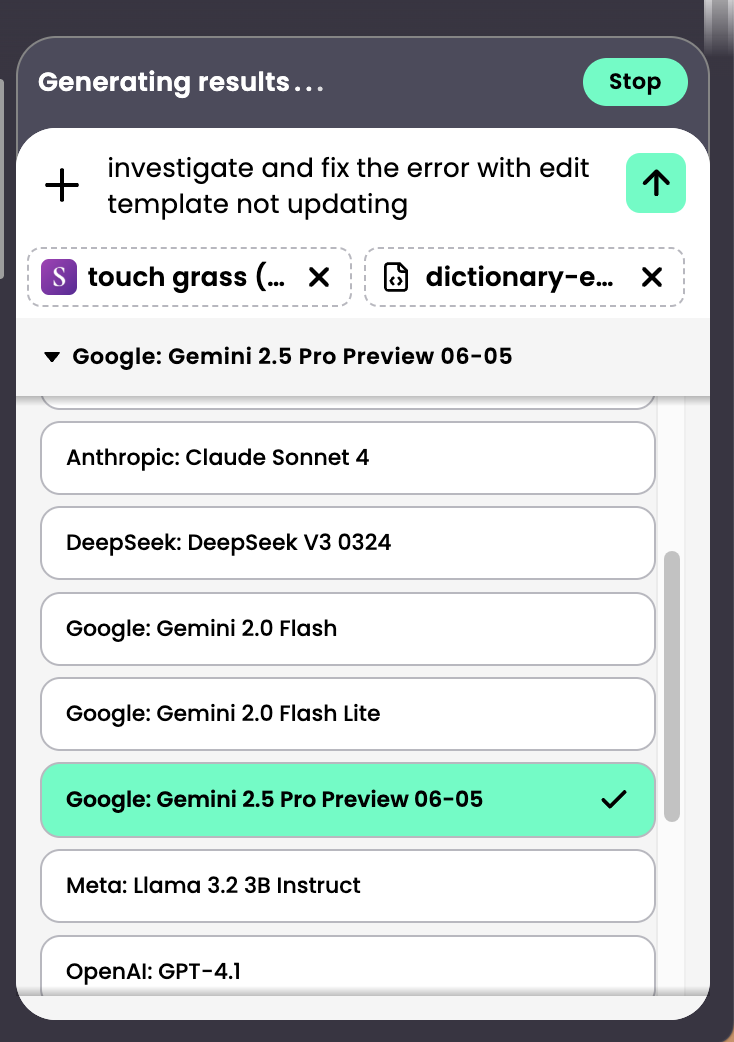
If you want to see what’s sent to the LLM, turn on debug mode by adding ?debug=true to the URL (&debug=true if query parameters already exist).
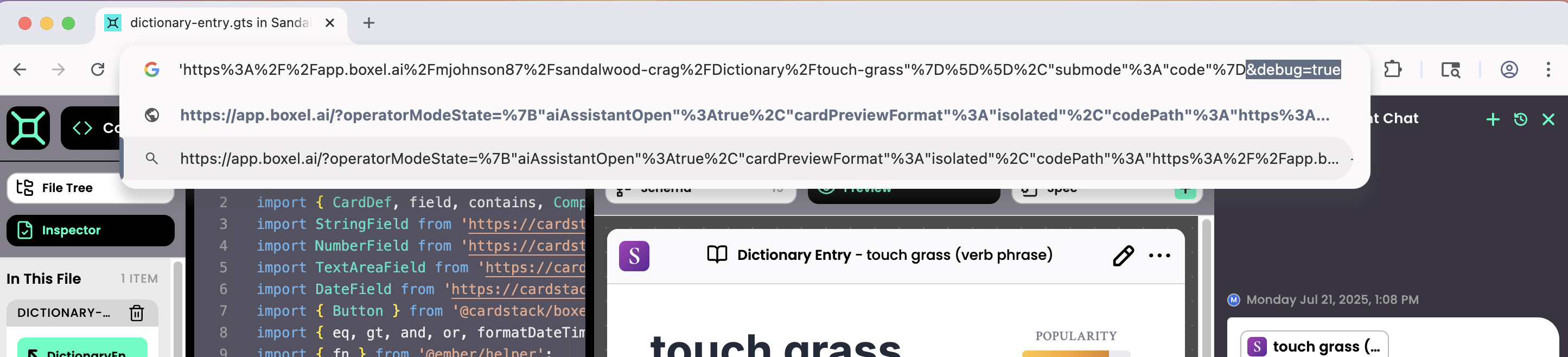
When stubborn problems occur, enable debug=true; the agent will show the exact payload sent to the LLM, which you can download and inspect or share with customer support to determine whether the issue is platform‑related or specific to your project.